Introduction
High availability enables your IT infrastructure to function continuously though some of the components may fail. High availability plays a vital role in case of a severe disruption in services that may lead to severe business impact.
It is a concept that entails the elimination of single points of failure to make sure that even if one of the components fail, such as a server, the service is still available.
Failover
Failover is a process. Whenever a primary system, network or a database fails or is abnormally terminated, then a Failover acts as a standby which helps resume these operations.
Failover Cluster
Failover cluster is a set of servers that work together to provide High Availability (HA) or Continuous availability (CA). As mentioned earlier, if one of the servers goes down another node in the cluster can take over its workload with minimal or no downtime. Some failover clusters use physical servers whereas others involve virtual machines (VMs).
CA clusters allow users to access and work on the services and applications without any incidence of timeouts (100% availability), in case of a server failure. HA clusters, on the other hand, may cause a short hiatus in the service, but system recovers automatically with minimum downtime and no data loss.
A cluster is a set of two or more nodes (servers) that transmit data for processing through cables or a dedicated secure network. Even load balancing, storage or concurrent/parallel processing is possible through other clustering technologies.
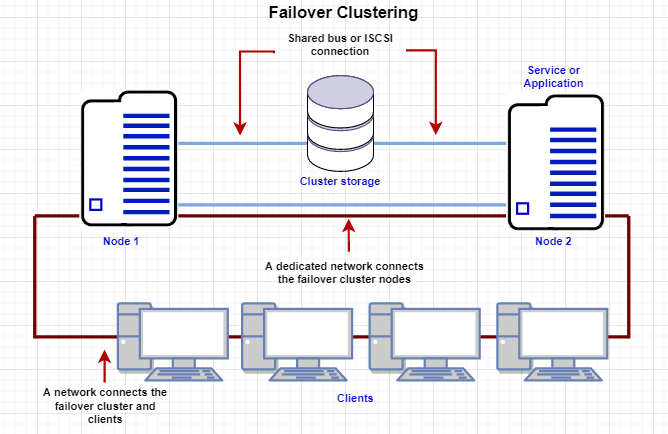
If you look at the above image, Node 1 and Node 2 have common shared storage. Whenever one node goes down, the other one will pick up from there. These two nodes have one virtual IP that all other clients connect to.
Let us take a look at the two failover clusters, namely High Availability Failover Clusters and Continuous Availability Failover Clusters.
High Availability Failover Clusters
In case of High Availability Failover Clusters, a set of servers share data and resources in the system. All the nodes have access to the shared storage.
High availability clusters also include a monitoring connection that servers use to check the “heartbeat” or health of the other servers. At any time, at least one of the nodes in a cluster is active, while at least one is passive.
Continuous Availability Failover Clusters
This system consists of multiple systems that share a single copy of a computer’s operating system. Software commands issued by one system are also executed on the other systems. In case of a failover, the user can check critical data in a transaction.
There are a few Failover Cluster types like Windows Server Failover Cluster (WSFC), VMware Failover Clusters, SQL Server Failover Clusters, and Red Hat Linux Failover Clusters.
Windows Server Failover Clustering (WSFC)
One of the powerful features of Windows Server is the ability to create Windows failover clusters. With Windows Server 2019, Windows Failover Clustering is more powerful than ever and can host many highly available resources for business-critical workloads.
Following are the types of Windows Server 2019 Failover Clustering:
- Hyper-V Clustering
- Clustering for File Services
- Scale-Out File Server
- Application Layer Clustering
- Host Layer Clustering
- Tiered Clustering
Each provides tremendous capabilities to ensure production workloads are resilient and highly available.
Windows Server 2019 Failover Clustering supports the new and demanding use cases with a combination of various cluster types and applications of various clustering technologies.
Windows Server Failover Clustering (WSFC) is a feature of the Windows server platform for improving the high availability of clustered roles (formerly called clustered applications and services). For example, say there are two servers. They communicate through a series of heartbeat signals over a dedicated network.
Supported Target Version
| Supported Target Versions |
|---|
| Windows Server 2019 |
Hierarchy of Windows Failover Cluster
If you select Windows Type as CLUSTER, Application will discover the Windows Fail-Over Cluster Related Resources.
- Windows Failover Cluster
- Windows Cluster Node
- Windows Cluster Shared Volume
- Windows Cluster Disk
- Windows Cluster Role
If you select Windows Type as STANDALONE, application can discover the Windows Node Related Resource.
- Windows Node
Version History
| Application Version | Bug fixes / Enhancements |
|---|---|
| 10.0.2 | Fixed cluster generic service status metric data collection. |
| 10.0.1 | Resolved issue for Node CPU Core Utilization Metric Components. |
| 10.0.0 | Persona support for Windows Fail-over Cluster Standalone Node. |
| 9.0.0 | Added support for monitoring windows_cluster_node_system_ThreadsPerCore metric on Windows Cluster Node Native Type. |
| 8.0.0 |
|
| 7.1.1 |
|
| 7.1.0 |
|
| 7.0.1 | Removed resourceName prefix from the attributes make & model for native type Windows HyperV Server. |
| 7.0.0 |
|
| 6.0.0 |
|
| 5.0.2 | Set the Node IP by filtering the networks based on the role ClusterAndClient. |
| 5.0.1 | Activity log changes & latest metric snapshot changes. |
| 5.0.0 | Provided additional metric support on Windows Failover Cluster native type for NetWork State and Network Interface State metrics. |
| 4.0.0 | Added Physical Disk and Roles as new resource types. |
| 3.0.3 | Power shell script fix to close the session in case of failures. |
| 3.0.2 | Fixed metric component alerting issue. Users can enable/disable alerting for specific metric components. |
Click here to view the earlier version updates
| Application Version | Bug fixes / Enhancements |
|---|---|
| 4.0.0 |
|
| 3.0.1 | Metric label support added. |
| 3.0.0 | Added monitoring support for cluster shared volume. |
| 2.1.3 | Full discovery support added. |
| 2.1.2 |
|
| 2.1.1 | Added support to alert on gateway in case initial discovery fails with connectivity/authorization issues. |
| 2.1.0 | Removed Port from Windows cluster app configuration page. |
| 2.0.0 | Initial sdk app discovery & monitoring implementation. |
- See, Working with Windows failover cluster monitoring for more information on how to configure Windows failover cluster monitoring.
- See Supported Metrics and Default Monitoring Configuration for more information about Supported Metrics and Default Monitoring Configuration of Windows failover cluster monitoring.
- See Supported Alert and Resource Filter Input keys for more information about Supported Alert and Resource Filter Input keys of Windows failover cluster monitoring.
- See Risk, Limitations and Assumptions for more information about the Risk, Limitations and Assumptions of Windows failover cluster monitoring.